
It’s never fun to move your current content to a new system. Some solutions claim to do it without any effort. The result can be like a photo of a Lego model: it looks nice, but you can’t build new things with it. We migrate content automatically, but keep all the original information. Your translations, reuse, and metadata are all safe, and you own the conversion tools so you can tweak as you like.
We convert the following formats into structured, semantic standards such as DITA XML and S1000D:
- Semi-structured content — Author-IT, MadCap Flare
- Structured content — DocBook and other XML/SGML formats
- Unstructured content — MS Word, unstructured FrameMaker, InDesign
To produce high quality converted content, we build a model of your target structures, analyse your current content, define mappings and any manual enrichment needed, and finally develop and test the conversion script.
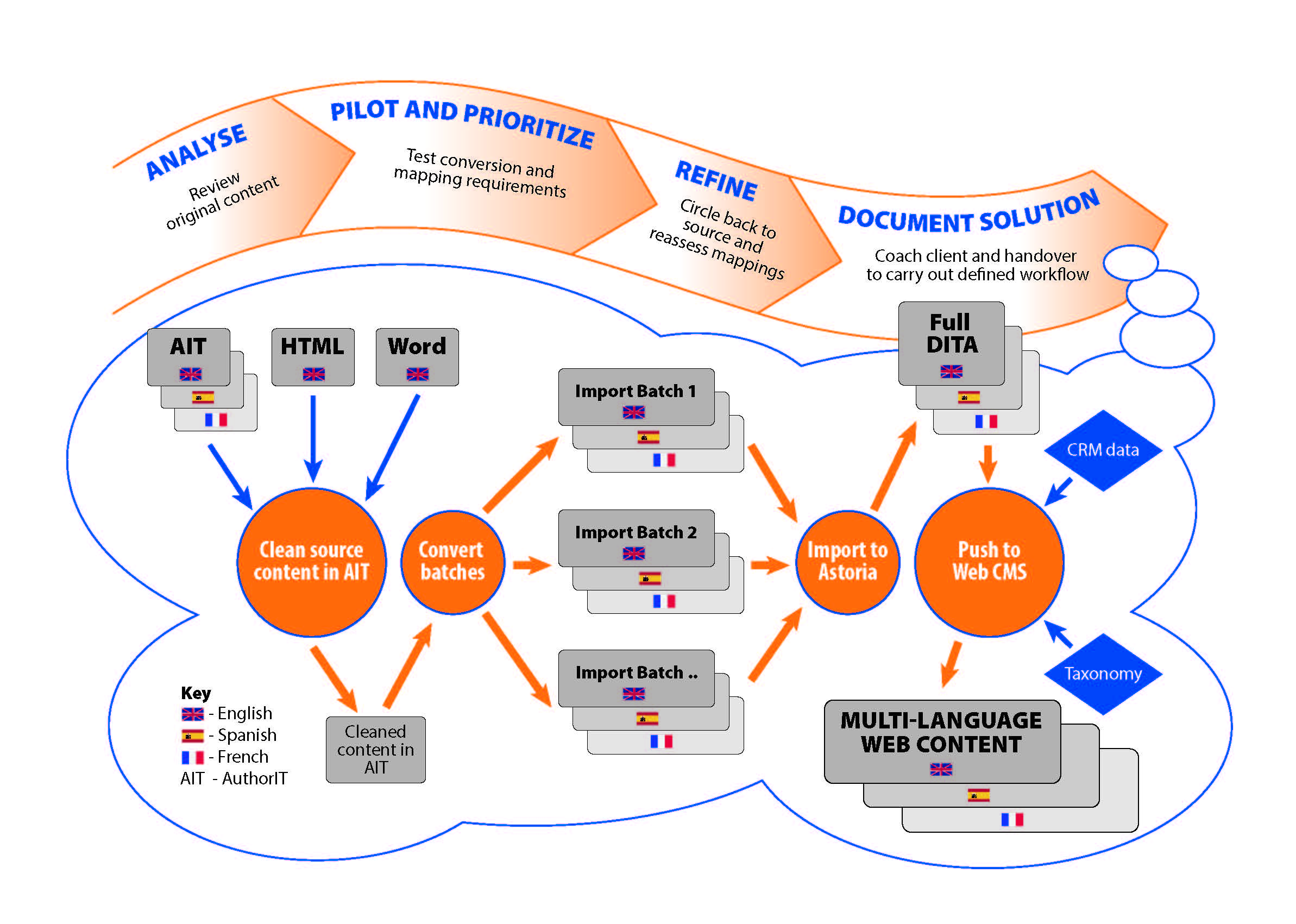
Typical Phases in a Content Migration Project

These are typically not undertaken sequentially, but iteratively. Only the final phase, the migration itself, is undertaken after all the other steps have been completed.
Phase 1: Analyse source content and build information model
The first phase involves Contiem specialists building an information model with your team. This enables clear target structure mappings to be defined between your existing content and the equivalent target structures. Major areas to cover include:
|
Map structure
|
Structuring publications consistently so that all output requirements can be handled and other authors can reuse the content efficiently.
|
|
Topic/section types
|
Specify types of information chunk to provide consistent, clear information for users as well as easier processing and management.
|
|
Element usage
|
Define which elements will be used within sections in a consistent and easy to process way.
|
|
Object names and metadata
|
Name and tag files/database objects appropriately.
|
|
Image formats and usage
|
Specify the file formats and expected dimensions of images.
|
|
Reusing content
|
Define target structures for reusable modules and snippets. Priorities are consistency, accuracy, and maintainability.
|
From the information model, we help you develop a definitive set of test content. The target is to produce a representative sample that includes all relevant mapped structures i.e. every topic/section type, element, image format, and different sequences of those items, where that could make a difference to the output. This will ensure repeatable, consistent testing of the migration script(s) developed later in the conversion process, is possible.
We produce mocked-up and marked-up conversion output, as well as a complete specification of the mapping between the legacy content structures and the new structures.
Phase 2: Add contextual cues where required and clean up legacy content
Where the source content is unstructured, or a legacy schema is less constrained than the target schema for migration, it is sometimes helpful to add extra semantic information and clean up the legacy content, so it maps more easily and systematically to the target structures.
A simple example is that if you wish to convert a DocBook section to several DITA task topics, you would first open out the DocBook section into several nested section files, structure them in a way that corresponds to DITA tasks, and then name them with a “t-” prefix so that the conversion script could take the appropriate action to convert them to task topics.
This process can only be undertaken once a draft information model has been defined and once authors have access to the legacy content to be able to make such changes.
Phase 3: Develop and test migration scripts
The last phase of the conversion process involves developing a customized, often XSLT-based migration script, using the mappings and information model developed in the earlier phases. This is a highly iterative process and the script will make use of the previously defined sample test input, along with the sample marked up output for comparative purposes. The output may be the same dedicated DITA maps that were used to test publishing. In which case, the input will be legacy structures that are expected to be mapped to those target DITA structures, including any necessary extra contextual cues.
When Contiem develops these scripts for our clients, using the initial content sample helps to get the development process started, but it is vital to also test the process with real content. There will always be new structures or sequences that have not previously been accounted for, and the script will need to be adjusted to reflect this. Doing such custom script development leads to a high-quality conversion that preserves the semantics of the original content and the reuse within that content. A good conversion script will only convert each reused topic once, and will map legacy reuse patterns to idiomatic target architectural patterns.
Phase 4: Schedule conversion according to clusters of reuse
It is rare for an organization to be able to convert all content at the same time. It is unlikely that every group of authors will be ready to move to the new architecture at the same time. However, to maximise reuse and simplify script development, it is helpful to convert content in batches according to the clusters of reuse within that content. For example, it might make sense to convert all installation manuals at one time, due to some reuse between them, and convert web services docs in a subsequent batch. It is possible to migrate individual documents from a set like this, and others from the same set later, but it requires developing a more complex conversion tool that can store the paths or IDs of files already converted. With this approach of course, there is always a potential risk that reused content may be modified between a first and subsequent import.
If you would like to find out more about how Contiem can help with your content migration, email