This time we’re going to look at how indirect referencing works as a mechanism for reuse. But in order to understand indirect addressing for re-use, let’s recap a little about direct referencing. Even if you are new to DITA, you might be aware of the idea of ‘conreffing’ content from one place to another – it’s become a verb in its own right among DITA users. When we talk about ‘conreffing’ content we’re actually talking about the use of an attribute – @conref that is applied to an element.
The @conref attribute creates a direct relationship between two topics – content from one topic is referenced in another – or in many places.
@conrefs can be useful when you have text that needs to be consistent throughout the document set – that might mean a copyright statement that can’t change because the legal team have signed it off – or it might be that there are particular phrases and words, such as product names that you want to conform to the company style guide.
For example, in this DITA topic we have a list of possible safety warnings:
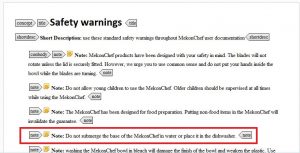
We can then reuse those warnings in other topics: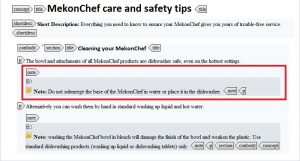
Most XML editors that support DITA will give you visual cues that the text is referenced – so you know that you can’t edit it.
Reusing content by conref is a simple and powerful way to reuse fixed content and cascade changes through the content set.
But, as with the links we looked at last time, the referenced content will travel with the topic wherever it is used – whether it’s relevant or not. Sometimes that is fine and a @conref is exactly what you need. But in other situations you may want the referenced content to vary depending on where it is used – and that’s where the @conkeyref attribute is useful.
Imagine you have a topic about returning a product – the core of the content is generic, but you have text that varies, such as the address, the company website and the exact piece of consumer rights legislation that applies in the UK and the US.
We can store these US and UK-specific variables in two dedicated topics. Here are the UK values:

And here are the US values:
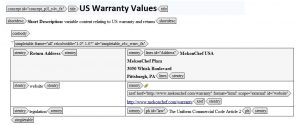
For each of the elements we want to reuse, I’ve assigned a memorable ID. In each topic, the variable text has the same ID e.g. ‘Address’ for the postal address, ‘law’ for the name of the legal statute, ‘website’ for the web address.
In the DITA Map, I’ve set up a Key, called WarrantyVariables that points to the US variables topic: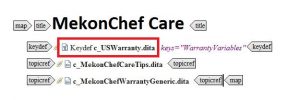 This means that the topic picks up variable values from the document c_USWarranty.dita:
This means that the topic picks up variable values from the document c_USWarranty.dita:
Within my generic topic, I use the @conkeyref attribute to point to the element I want to reuse – note that there is no file path used here, making the syntax much easier:

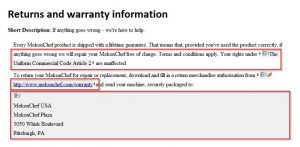
If I change the Key Definition so that it points to the topic with the UK variables:
The UK variables are picked up in the generic topic:
What would otherwise be a very specific topic therefore becomes generic and reusable – and if the need arises for additional sets of variables (for example to cover the EU) then it is straightforward to set them up.
View more Bitesize DITA tips, tricks and insights
If you have a question or a useful tip to share, why not tweet us @BiteSizeDITA
DITA Training
Looking to develop your DITA skills? Book your place on one of our DITA training courses. Contiem offer a range of DITA training to suit your specific needs:
Our specialist training courses can be delivered as a standalone training course, or as part of an integrated, customised solution. We deliver our courses in a number of ways, here at Contiem, on site with you or remote.