Bitesize DITA is written by Rachel Johnston, Contiem.
Variation in product names, product families, branding, and functionality across similar manual sets has always been a headache for technical authors. When Help Authoring Tools first featured conditional text it seemed like a godsend. But, when the only tool you have is a hammer, everything looks like a nail and authors found that conditions rapidly got out of hand. As conditions were a primary way to manage content variation, authors were forced to use them to manage a whole array of complex single-sourcing scenarios via a rainbow of colour coding and a profusion of check boxes. Knowing which set of conditions to apply to get a particular result became folkloric knowledge that authors would accrue over time and that new authors would have to pick up as they went along.
DITA is a bigger and deeper toolbox, and over the next few Bitesize DITA articles we’ll be looking at the options for managing conditions in a sane and sensible way.
But first, let’s look at how filtering works in DITA. Filtering is the closest thing to the conditional text functionality you find in most Help Authoring Tools and the mechanism is fairly similar – you identify the content you want to filter in the DITA source, then at publishing time you instruct the publishing engine to use a particular set of filtering criteria (called a DITAVAL file). DITAVAL files are independent of the map you are filtering and can be reused.
You can filter content on any DITA attribute, but the DITA standard includes a common set of attributes intended for profiling purposes, that are applicable to nearly all DITA elements:
- audience
- platform
- product
- otherprops
Let’s use the @audience attribute as an example. Many training courses include special content aimed at the instructors that doesn’t get published in the student materials:

The content aimed only at the course instructor is held in the lcInstructornote2 element:
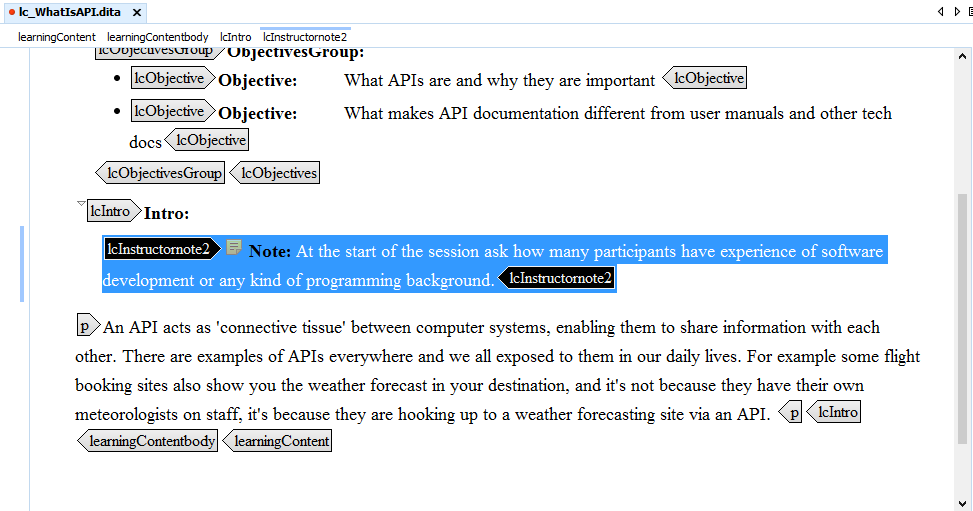
To make a student guide that filters out the content in the instructor note we need to add an attribute to the lcInstructornote2 element:

We can then set up a DITAVAL file to exclude any element where the @audience attribute is set to “instructor”:
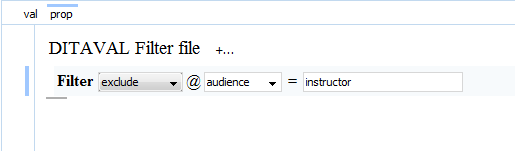
When the map is published, the DITA Open Toolkit excludes the instructor note because we’ve instructed it to exclude anything where audience=”instructor”:

You can also filter content out at topic level – by appling profiling attributes to the topicref element:
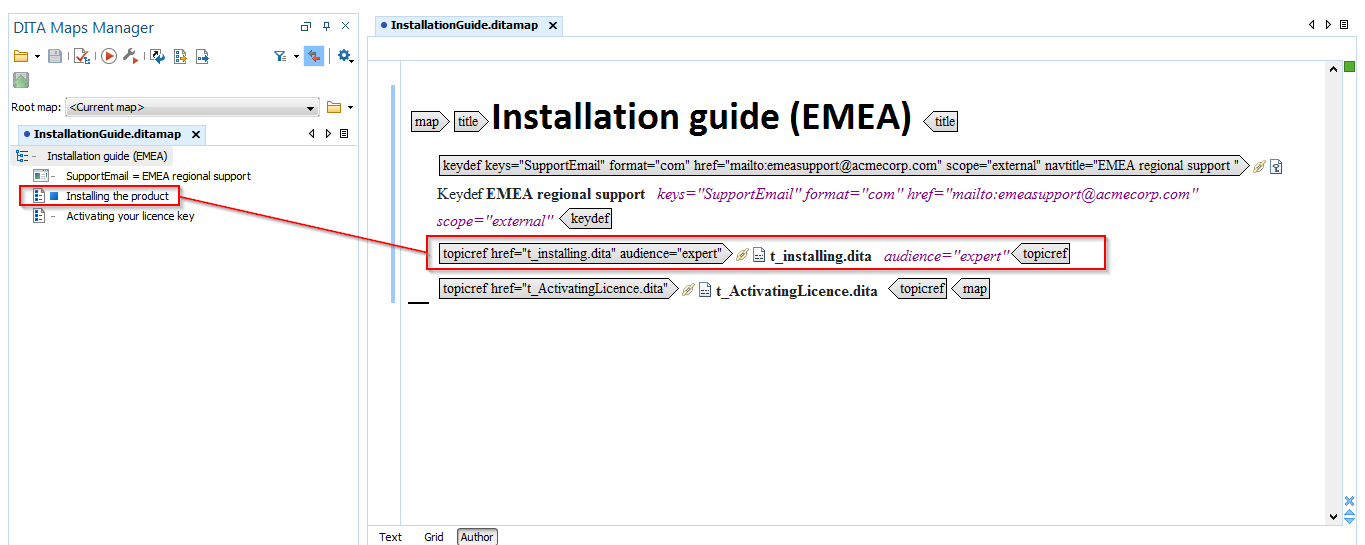
Limitations of Filtering
Filtering using DITAVAL works best with small numbers of ‘closed’ sets of attributes that don’t overlap too much and where the boundaries of what’s in and what’s out are really clear. In the example above, content is either in the instructor guide, or it’s not.
Some of the problems with conditions in DITA are the same as any other technology – if conditions are set up and applied without due care and attention, a mess can quickly develop. If you conditionalise content based on criteria that are expanding (for example product names) the number of different filters that need to be applied will quickly proliferate.
For example, filtering on whether a mobile phone manual is IOS or Android can be effective because new mobile operating systems don’t come along very often. But filtering on the OS, OS version, product family, brand name and series code is likely to result in chaos.
Asking authors to pick combinations from a huge list of conditions is error prone. Also, if parts of the content apply to product A, parts to product B, parts to products C and D and other parts only to A and D it can be extremely hard to keep track of whether conditions have been applied correctly and if the document has been published with the correct conditions turned on.
It’s therefore really important to plan your conditional publishing strategy in advance. There will always be change, but if you let conditions grow organically you might realise later that a different approach could have been simpler. For example if 13 out of 15 your software’s features are unavailable in China, it might be easier to focus your conditions on regions rather than features so that you can apply a single filtering attribute. As with other aspects of DITA there are often many ways to achieve the same goal, and the work of the Information Architect is to decide which one is the most practical, scalable and future-proof approach.
The fact that attributes are free text can also cause problems if authors do not spell and capitalise consistently – so one author may set the platform attribute as “Android” and another for “android”. So governance is also important – it’s helpful if a single team member can act as a responsible person in relation to conditions – checking their usage, making decisions in relation to change requests, generating new DITAVAL files and documenting the writing guidelines.
Having looked at the capabilities and limitations of conditions themselves, in the next Bitesize DITA article we will look at the other approaches to variable content that DITA offers.
View more Bitesize DITA tips, tricks and insights
If you have a question or a useful tip to share, why not tweet us @BiteSizeDITA
DITA Training
Looking to develop your DITA skills? Book your place on one of our DITA training courses. Contiem offer a range of DITA training to suit your specific needs:
- Introduction to DITA
- DITA Authoring with oXygen XML Author
- Getting started with the DITA Open Toolkit training
- Customising the DITA Open Toolkit
Our specialist training courses can be delivered as a standalone training course, or as part of an integrated, customised solution. We deliver our courses in a number of ways, here at Contiem, on site with you or remote.