Bitesize DITA is written by Rachel Johnston, Contiem.
In the previous article, we looked at the problems that over-use, or inappropriate use of conditions and filtering can bring – this time we’re going to explore the thought processes and decisions behind managing variable content.
Scenario 1: content that changes unnecessarily
Before you think about how to manage variation, ask yourself, is that variation really necessary? There are two aspects to this. Firstly, when content is written for different purposes, by different authors variation can creep in organically and part of the work of an information architect is to iron out unnecessary variation.
Secondly, authors may include unnecessary detail, for example product names that don’t really add to the meaning of the topic, but that make it specific. There is always a trade off between how specific a topic is to a particular circumstance, and how reusable it is.
For example:

In this situation, the specifics of the product name don’t give the user any additional information, so you can merge the two topics into one generic one:

If you can see a clear need for the variation between topics – if the changing content genuinely adds valuable information and depth to the content, you then need to figure out what kind of variation it is, and how best to manage it.
Scenario 2: Content that changes reliably and often
If the variable content is more often different than it is the same, and if those differences are likely to keep growing, then the most sensible approach is to use keys. For larger chunks of content, you can use the @conkeyref attribute. For strings and links you can use @keyref.
For example, in a topic where you may always want to include specific snippets of the same kind of information, but where those snippets vary a lot, or where new variations are likely to come along frequently.
In this example, the generic topic will always need the legal details, local web address and return merchandise address. Potentially each different region will need its own details, so the set of conditions could potentially expand quite quickly – and if the author was using conditions and filtering – the number of individual conditions and the length of the topic could expand very quickly.
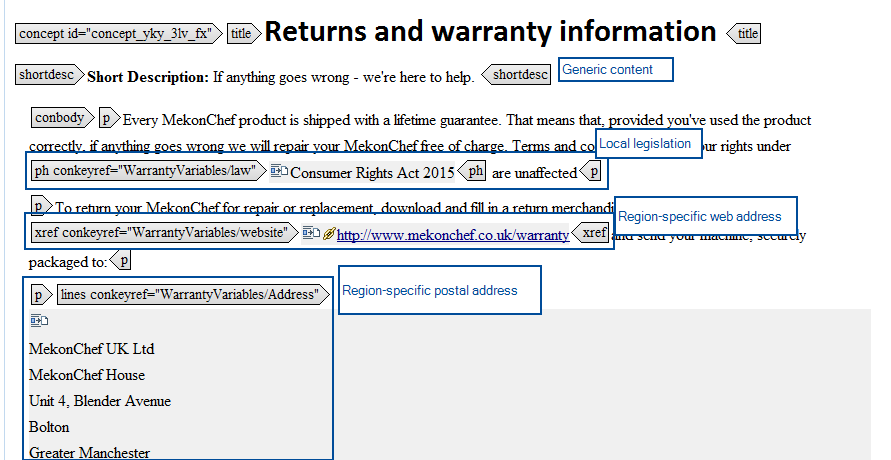
Scenario 3 – a stable list of conditions
If the topic varies on the basis of conditions that don’t really change (i.e. you won’t be asked to accommodate new ones), you can add all the variants to the same topic and filter accordingly.
For example, if a topic contains measurements, and different versions are required for Europe (using metric) and the US (using imperial) then you can use a DITAval file to exclude the measurements that do not apply:
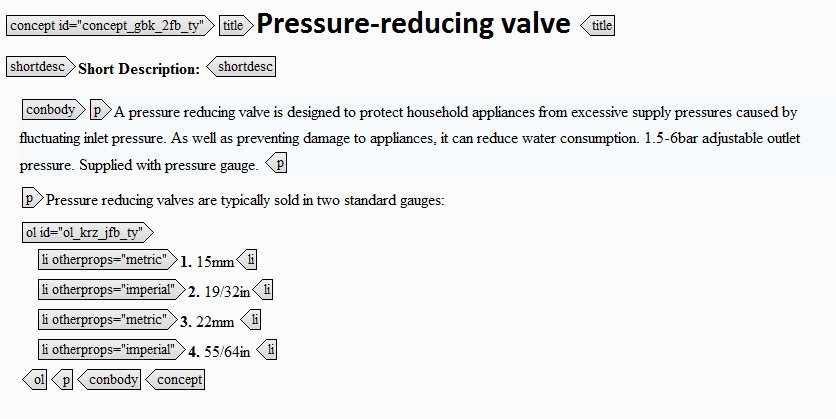
In theory, this is a good use of conditions because a particular measurement can only be metric or imperial – it can’t be both, and it can’t be neither. But of course you’d need to be careful that you’d done your conversions correctly and that when one measurement changed, its equivalent value changed too.
Scenario 4: none of the above
These are the two most commonly used and useful ways to handle variation and reuse – in future articles we will look at some alternative approaches such as @conrefpush and the new branch filtering capabilities that version 1.3 of the DITA specification brings. The important thing is to find out what works for your situation and stick to it, through careful analysis of the content and planning your approach not just for content that exists now, but for content you may need in the future. .
If managing the difference between variant topics is too complex, too error prone, or the differences are too nuanced to manage using any of the above methods, consider keeping the variant content as multiple variant topics. The aim of the exercise isn’t reuse at any cost – it’s reuse that makes authoring easier and more efficient. If wrangling particular variables is giving you a headache, it may be time to revisit the idea of forking the content into separate topics and managing it through different maps, especially if you have a CCMS that can manage the relationships between topics for you. it’s one of the beauties of DITA that we have this toolbox of techniques from which we can pick an approach that works.
If you have challenges around variables, reuse or any other aspect of your DITA information model, Contiem can help. We can work with you in a way that suits your needs and budget, from short training courses to consultancy engagements and long-term coaching programmes. Find out more.
View more Bitesize DITA tips, tricks and insights
If you have a question or a useful tip to share, why not tweet us @BiteSizeDITA